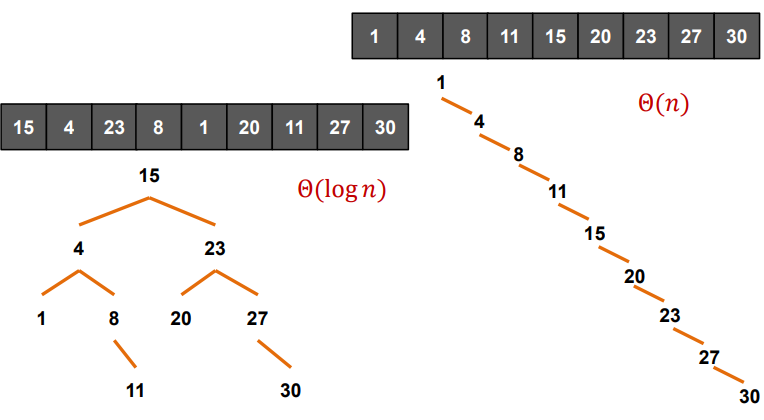
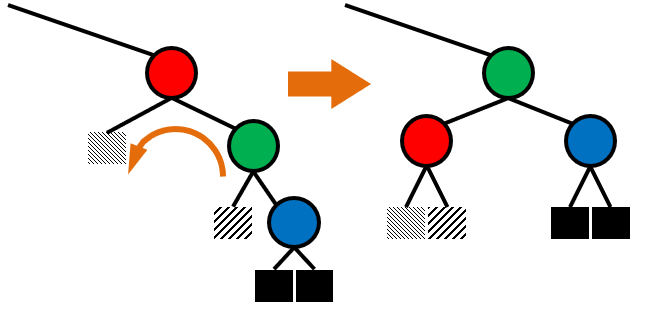
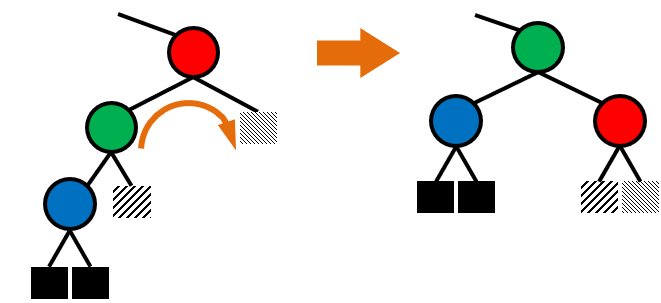
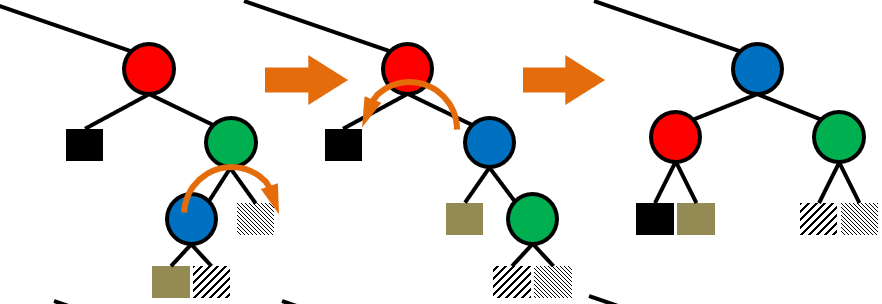
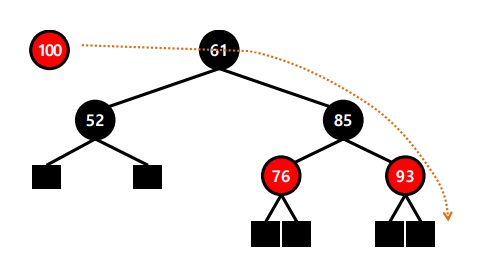
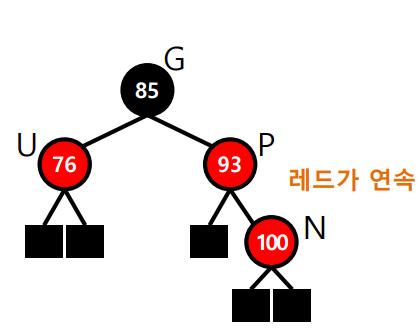
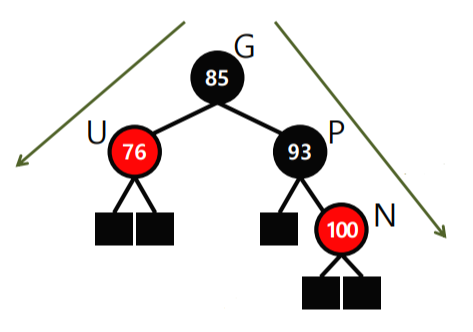
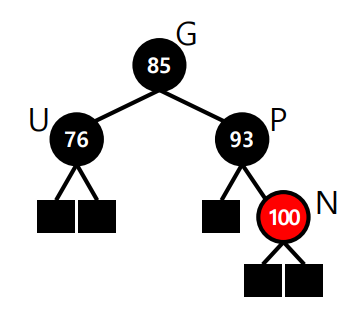
####### Binary Search ######
import random
from timeit import default_timer as timer
def binary_search(x, v):
start = 0
end = len(x) - 1
while start<=end:
mid = (start+end) // 2
if x[mid] == v : return mid
elif x[mid] < v : start = mid + 1
else: end = mid - 1
return -1
x = random.sample(range(5000), 1000)
x.sort()
value = x[800]
start = timer()
index = binary_search (x, value)
print(timer() - start)
print('value ', value, 'found ', index)
print(True if index >=0 and x[index] == value else False)
c++ 코드
#include <iostream>
#include <algorithm>
using namespace std;
int A[10];
int binary_search(int target)
{
int start = 0, end = 9;
int mid;
while (start <= end)
{
mid = (start + end) / 2;
if (A[mid] == target) return mid;
else if (A[mid] > target) end = mid - 1;
else start = mid + 1;
}
return -1;
}
int main()
{
srand(time(NULL));
for (int i = 0; i < 10; i++)
{
A[i] = rand() % 100;
}
sort(A, A + 10);
int index = binary_search(A[3]);
cout << "A[3] = " << A[3] << endl;
if (index > -1)
cout << "index = " << index << ' ' << "A[index] = " << A[index] << endl;
else
cout << "error";
}
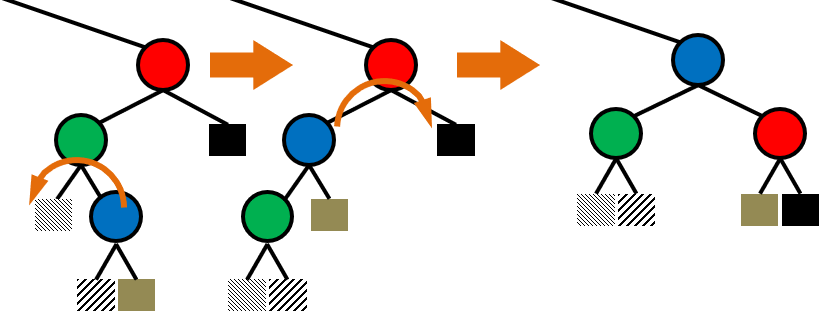
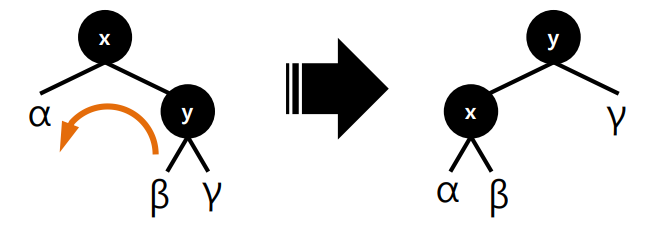
이진 검색 트리 ( Binary Search Tree )
이진 검색 트리란?
왼쪽 자식은 부모보다 작고 오른쪽 자식은 부모보다 큼
각 노드는 하나의 키 값을 가진다.
각 노드의 키 값은 모두 달라야 한다.
각 노드는 최대 두 개의 자식 노드를 갖는다.
각 노드의 키 값은 왼쪽의 모든 노드의 키 값보다 크고 오른쪽의 모든 노드의 키 값보다 작다.
Insert, Search, Delete
Insert
작으면 왼쪽 크면 오른쪽으로 넣음
Search
작으면 왼쪽 크면 오른쪽 찾음
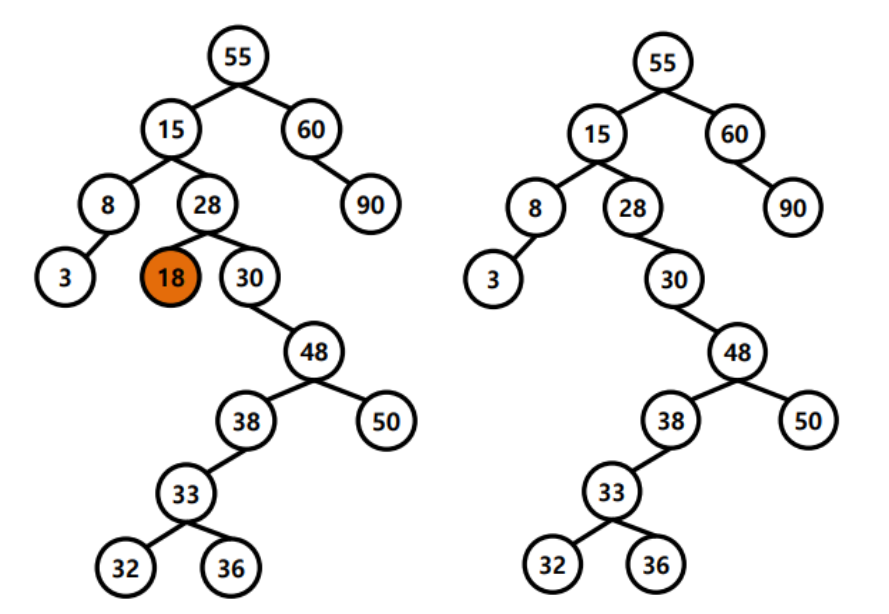
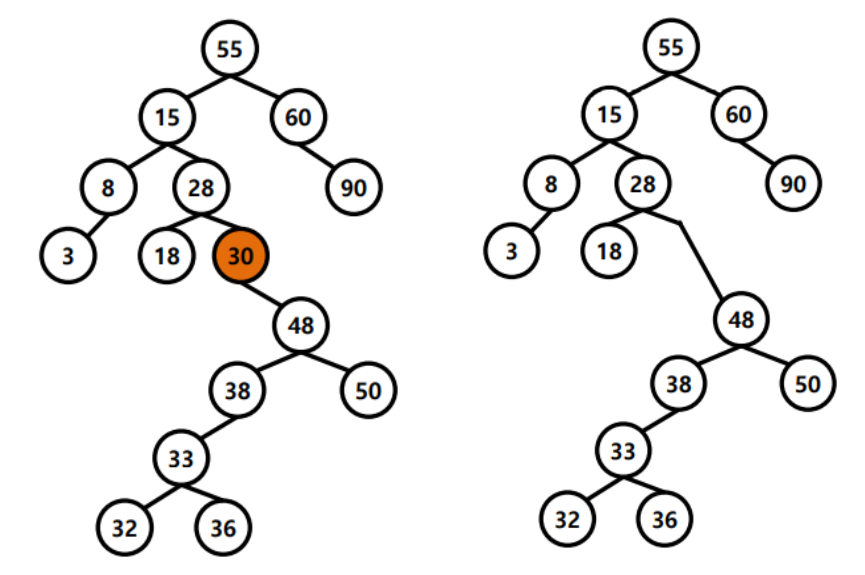
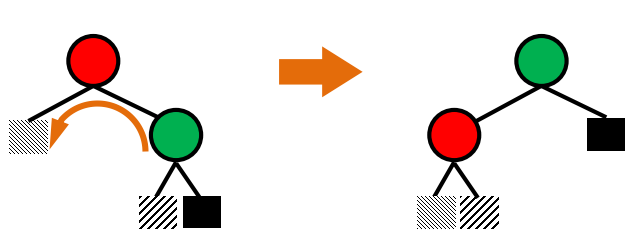
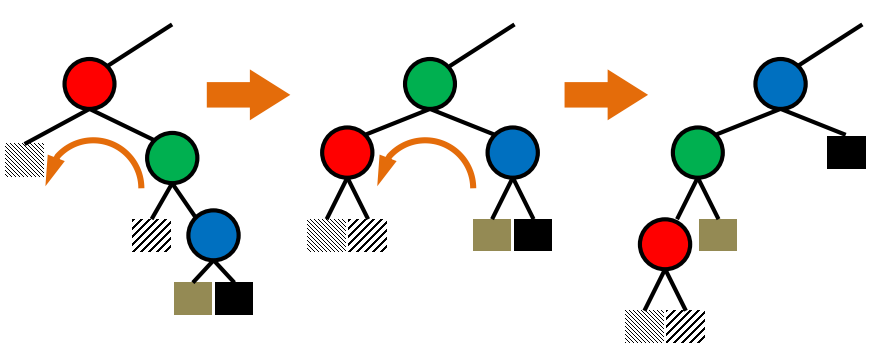
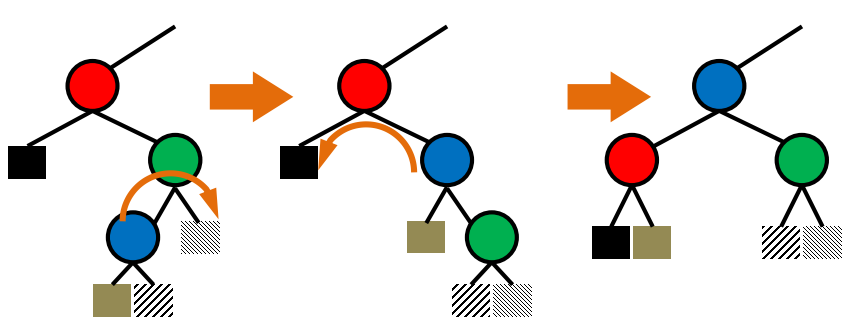
Delete
1. 자식 노드가 0개인 경우 : 그냥 지움
2. 자식 노드가 1개인 경우 : 부모와 자식 이어줌
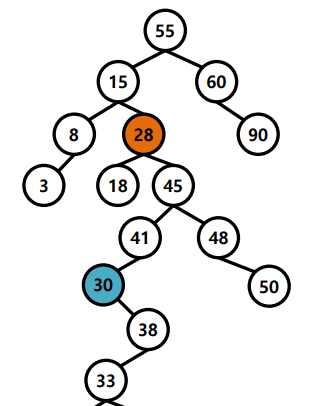
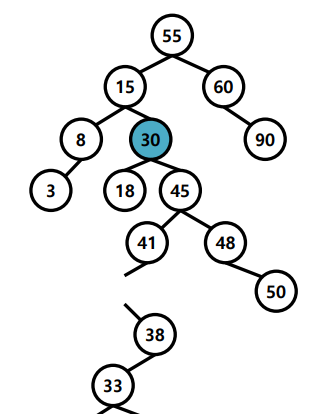
3. 자식 노드가 2개인 경우 :
오른쪽 자식에서 제일 작은 노드를 찾는다. ( 왼쪽 자식보다 큰 노드 중에서 가장 작은 노드 )
delete하고 위에서 찾은 노드를 위로 올린다.
빈 노드는 자식이 최대 하나이므로 위에서 설명한 것처럼 잇는다.
이진 검색 트리의 단점
데이터 입력 순서에 따라 성능이 달라진다.
python 코드
import random
from timeit import default_timer as timer
class Node(object):
def __init__(self, key, parent):
self.key = key
self.left = None
self.right = None
self.parent = parent
def insert(node, key, parent):
if node is None :
node = Node(key, parent)
elif key < node.key :
node.left = insert(node.left, key, node)
else : node.right = insert(node.right, key, node)
return node
def search(node, key):
if node is None or node.key == key: return node
if key < node.key : return search(node.left, key)
return search(node.right, key)
def delete_node(node):
if node.left is None and node.right is None :
return None
elif node.left is not None and node.right is None :
return node.left
elif node.left is None and node.right is not Node :
return node.right
else:
s = node.right
while s.left is not None :
sparent = s
s = s.left
node.key = s.key
if s == node.right :
s.right.parent = node
node.right = s.right
else :
s.right.parent = sparent
sparent.left = s.right
return node
def delete(node) :
if node.parent is None : node = None
elif node is node.parent.left : node.parent.left = delete_node(node)
else : node.parent.right = delete_node(node)
x = [10,20,30]
value = 30
root = None
for i in x:
root = insert(root, i, None)
start = timer()
found = search(root, value)
print(timer()-start)
if found is not None:
print('value', value, 'found', found.key)
print(True if found.key == value else False)
delete(search(root, value))
found = search(root, value)
void selection_sort()
{
int arr[10] = { 1,3,5,6,8,2,4,10,7,9 };
int largest_index;
for (int i = SIZE - 1; i > -1; i--)
{
largest_index = i;
for (int j = i; j > -1; j--)
{
if (arr[largest_index] < arr[j])
largest_index = j;
}
int temp = arr[largest_index];
arr[largest_index] = arr[i];
arr[i] = temp;
}
}
Python 코드
import random
from timeit import default_timer as timer
def selection_sort(x):
for last in range(len(x)-1, 0, -1):
largest = 0
for i in range(1, last+1):
if x[i] > x[largest]:
largest = i
x[largest], x[last] = x[last], x[largest]
def test(x):
for i in range(1, len(x)):
if x[i-1] > x[i]:
return False
return True
data = [1, 3, 5, 6, 8, 2, 4, 10, 7, 9]
start = timer()
selection_sort(data)
print(timer() - start)
print(data)
print(test(data))
void bubble_sort()
{
int arr[10] = { 1,3,5,6,8,2,4,10,7,9 };
bool flag = false; // stop option
for (int i = SIZE - 1; i > -1; i--)
{
for (int j = 0; j < i; j++)
{
if (arr[j] > arr[j + 1])
{
flag = true;
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
// stop option
if (!flag) break;
}
}
python 코드
import random
from timeit import default_timer as timer
def bubble_sort(A):
sorted = True # Termination conditions
for last in range(len(A) - 1, 1, -1):
for i in range(last):
if A[i] > A[i + 1]:
A[i], A[i + 1] = A[i + 1], A[i]
sorted = False
if sorted:
break
def test(A):
for i in range(1, len(A)):
if A[i - 1] > A[i]:
return False
return True
x = random.sample(range(10000), 100)
start = timer()
bubble_sort(x)
print(timer() - start)
print(x)
print(test(x))
void quick_sort_func(int list[], int left, int right)
{
if (left >= right) return;
int pivot = left;
int i = left + 1, j = right;
while (i <= j)
{
while (i <= right && list[pivot] > list[i]) i++;
while (j >= left && list[pivot] < list[j]) j--;
if (i > j) {
int temp = list[j];
list[j] = list[pivot];
list[pivot] = temp;
}
else {
int temp = list[i];
list[i] = list[j];
list[j] = temp;
}
}
quick_sort_func(list, left, j - 1);
quick_sort_func(list, j + 1, right);
}
void quick_sort()
{
int arr[10] = { 1,3,5,6,8,2,4,10,7,9 };
quick_sort_func(arr, 0, SIZE - 1);
print(5, arr);
}
python 코드
import random
from timeit import default_timer as timer
def partition(A, p, r):
x = A[r]
i = p
for j in range(p, r):
if A[j] <= x:
A[i], A[j] = A[j], A[i]
i+=1
A[i], A[r] = A[r], A[i]
return i
def qsort(A, p, r):
if p<r:
q = partition(A,p,r)
qsort(A, p, q-1)
qsort(A, q+1, r)
def quick_sort(A):
qsort(A, 0, len(A)-1)
def test(A):
for i in range(1, len(A)):
if A[i-1] > A[i]:
return False
return True
x = random.sample(range(10000), 100)
print(x)
start = timer()
quick_sort(x)
print(timer() - start)
print(x)
print(test(x))
힙 정렬
시간 복잡도
$ O(nlogn) $
힙 정렬이란?
최대 힙 / 최소 힙을 사용해서 정렬하는 것.
아래 코드에서는 최대 힙을 사용하였다.
최대 힙은 맨 위가 트리에서 가장 큰 원소이므로 최대 힙이 만들어지면 맨 위의 원소를 제외하고 또다시 최대 힙을 만드는 것을 반복하며 정렬한다.
c++ 코드
/*
* parent = (i-1)/2
* left = i*2 + 1
* right = i*2 + 2
*/
void make_heap(int n, int arr[])
{
for (int i = (n - 2) / 2; i > -1; i--)
{
int now = i;
int left = i * 2 + 1, right = i * 2 + 2;
int child = left;
if (arr[left] < arr[right] && right < n) child = right;
while (arr[child] > arr[now] && child < n)
{
int temp = arr[now];
arr[now] = arr[child];
arr[child] = temp;
now = child;
left = now * 2 + 1, right = now * 2 + 2;
if (arr[left] < arr[right] && right < n) child = right;
}
}
}
void heap_sort(int n)
{
int arr[10] = { 1,3,5,6,8,2,4,10,7,9 };
make_heap(n, arr);
for (int i = n - 1; i > -1; i--) {
int temp = arr[i];
arr[i] = arr[0];
arr[0] = temp;
make_heap(i, arr);
}
cout << "<heap_sort>" << endl;
for (int i = 0; i < n; i++)
cout << arr[i] << ' ';
}
기수 정렬 ( Radix sort )
시간 복잡도
$ O(n) $
n개의 원소를 k자릿수만큼 비교 => $ O(n) $을 $ k $번 반복 = $ O(n) $
기수 정렬이란?
입력이 모두 K 자릿수 이하의 자연수인 경우 자릿수 별로 안정성을 유지하며 정렬한다.
이때, 값이 같은 원소는 정렬 전후 순서가 바뀌지 않는다.
c++ 코드
int A[15] = { 123,2154,222,4,283,1560,1061,2150,3154,33,2234,345,677,8911,1 };
void rsort(int m, int n)
{
queue<int> bucket[10];
for (int i = 0; i < n; i++)
{
int index = A[i] / pow(10, m);
index %= 10;
bucket[index].push(A[i]);
}
int index = 0;
for (int i = 0; i < 10; i++)
{
while (!bucket[i].empty())
{
A[index++] = bucket[i].front();
bucket[i].pop();
}
}
}
void radix_sort()
{
int k = 4;
for (int i = 0; i < 4; i++)
rsort(i, 15);
cout << "<radix_sort>" << endl;
for (int i = 0; i < 15; i++)
cout << A[i] << ' ';
cout << endl;
}
python 코드
import random
from timeit import default_timer as timer
def rsort(A, m):
buckets = [[] for _ in range(10)]
for v in A:
index = v // (10 ** m)
index %= 10
buckets[index].append(v)
res = []
for bucket in buckets:
res.extend(bucket)
return res
def radix_sort(A, k):
for i in range(0, k):
A = rsort(A, i)
return A
def test(A):
for i in range(1, len(A)):
if A[i-1] > A[i]:
return False
return True
x = random.sample(range(10000),100)
start = timer()
x = radix_sort(x, 4)
print(timer() - start)
print(x)
print(test(x))
void counting_sort()
{
int n = 10;
int arr[10] = { 1,3,5,6,8,2,4,10,7,9 };
int count[11] = {};
int sortarr[10] = {};
for (int i = 0; i < n; i++)
count[arr[i]]++;
for (int i = 1; i < 11; i++)
count[i] += count[i - 1];
for (int i = 0; i < n; i++)
{
count[arr[i]]--;
sortarr[count[arr[i]]] = arr[i];
}
cout << "<counting_sort>" << endl;
for (int i = 0; i < n; i++)
cout << sortarr[i] << ' ';
cout << endl;
}
python 코드
import random
from timeit import default_timer as timer
def counting_sort(A, k):
B = [0] * len(A)
C = [0] * (k+1)
for v in A:
C[v] += 1
for i in range(1, k+1):
C[i] += C[i-1]
for i in range(len(A)-1, -1, -1):
v = A[i]
C[v] -= 1
B[C[v]] = v
return B
def test(A):
for i in range(1, len(A)):
if A[i-1] > A[i]:
return False
return True
x = random.choices(range(50), k=100)
start = timer()
print(x)
x = counting_sort(x, 49)
print(timer() - start)
print(x)
print(test(x))
팀 정렬
팀 정렬이란?
2002년 Tim Peters 가 개발
파이썬 버전 2.3부터 표준 정렬 알고리즘으로 사용
데이터가 정렬된 정도에 따라 삽입 정렬과 병합 정렬 사이를 전환하는 적응형 알고리즘
시간복잡도 비교
전체 코드
#include <iostream>
#include <algorithm>
#include <queue>
#include <cmath>
using namespace std;
#define SIZE 10
void print(int option, int list[])
{
switch (option) {
case 1:
cout << "<selection sort>" << "\n";
break;
case 2:
cout << "<bubble sort>" << "\n";
break;
case 3:
cout << "<insertion sort>" << "\n";
break;
case 4:
cout << "<merge sort>" << "\n";
break;
case 5:
cout << "<quick sort>" << "\n";
break;
}
for (int i = 0; i < SIZE; i++)
cout << list[i] << ' ';
cout << "\n";
}
void selection_sort()
{
int arr[10] = { 1,3,5,6,8,2,4,10,7,9 };
int largest_index;
for (int i = SIZE - 1; i > -1; i--)
{
largest_index = i;
for (int j = i; j > -1; j--)
{
if (arr[largest_index] < arr[j])
largest_index = j;
}
int temp = arr[largest_index];
arr[largest_index] = arr[i];
arr[i] = temp;
}
print(1, arr);
}
void bubble_sort()
{
int arr[10] = { 1,3,5,6,8,2,4,10,7,9 };
bool flag = false; // stop option
for (int i = SIZE - 1; i > -1; i--)
{
for (int j = 0; j < i; j++)
{
if (arr[j] > arr[j + 1])
{
flag = true;
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
// stop option
if (!flag) break;
}
print(2, arr);
}
void insertion_sort()
{
int arr[10] = { 1,3,5,6,8,2,4,10,7,9 };
for (int i = 1; i < SIZE; i++)
{
int loc = i - 1; //0
int now = arr[i]; //3
while (loc >= 0 && now < arr[loc])
{
arr[loc + 1] = arr[loc];
loc--;
}
arr[loc + 1] = now;
}
print(3, arr);
}
////////////////////////////////////////////////////////////////
void merge(int list[], int left, int mid, int right)
{
int merge_arr[SIZE];
int i, j, k;
i = left;
j = mid + 1;
k = left;
while (i <= mid && j <= right)
{
if (list[i] < list[j])
merge_arr[k++] = list[i++];
else
merge_arr[k++] = list[j++];
}
while (i <= mid)
merge_arr[k++] = list[i++];
while (j <= right)
merge_arr[k++] = list[j++];
for (int i = left; i <= right; i++)
list[i] = merge_arr[i];
}
void merge_sort_func(int list[], int left, int right)
{
int mid;
if (left < right)
{
mid = (left + right) / 2;
merge_sort_func(list, left, mid);
merge_sort_func(list, mid + 1, right);
merge(list, left, mid, right);
}
}
void merge_sort()
{
int arr[10] = { 1,3,5,6,8,2,4,10,7,9 };
merge_sort_func(arr, 0, SIZE - 1);
print(4, arr);
}
//////////////////////////////////////////////////////////////
void quick_sort_func(int list[], int left, int right)
{
if (left >= right) return;
int pivot = left;
int i = left + 1, j = right;
while (i <= j)
{
while (i <= right && list[pivot] > list[i]) i++;
while (j >= left && list[pivot] < list[j]) j--;
if (i > j) {
int temp = list[j];
list[j] = list[pivot];
list[pivot] = temp;
}
else {
int temp = list[i];
list[i] = list[j];
list[j] = temp;
}
}
quick_sort_func(list, left, j - 1);
quick_sort_func(list, j + 1, right);
}
void quick_sort()
{
int arr[10] = { 1,3,5,6,8,2,4,10,7,9 };
quick_sort_func(arr, 0, SIZE - 1);
print(5, arr);
}
//////////////////////////////////////////////////////////////
/*
* parent = (i-1)/2
* left = i*2 + 1
* right = i*2 + 2
*/
void make_heap(int n, int arr[])
{
for (int i = (n - 2) / 2; i > -1; i--)
{
int now = i;
int left = i * 2 + 1, right = i * 2 + 2;
int child = left;
if (arr[left] < arr[right] && right < n) child = right;
while (arr[child] > arr[now] && child < n)
{
int temp = arr[now];
arr[now] = arr[child];
arr[child] = temp;
now = child;
left = now * 2 + 1, right = now * 2 + 2;
if (arr[left] < arr[right] && right < n) child = right;
}
}
}
void heap_sort(int n)
{
int arr[10] = { 1,3,5,6,8,2,4,10,7,9 };
make_heap(n, arr);
for (int i = n - 1; i > -1; i--) {
int temp = arr[i];
arr[i] = arr[0];
arr[0] = temp;
make_heap(i, arr);
}
cout << "<heap_sort>" << endl;
for (int i = 0; i < n; i++)
cout << arr[i] << ' ';
cout << endl;
}
//////////////////////////////////////////////////////////
int A[15] = { 123,2154,222,4,283,1560,1061,2150,3154,33,2234,345,677,8911,1 };
void rsort(int m, int n)
{
queue<int> bucket[10];
for (int i = 0; i < n; i++)
{
int index = A[i] / pow(10, m);
index %= 10;
bucket[index].push(A[i]);
}
int index = 0;
for (int i = 0; i < 10; i++)
{
while (!bucket[i].empty())
{
A[index++] = bucket[i].front();
bucket[i].pop();
}
}
}
void radix_sort()
{
int k = 4;
for (int i = 0; i < 4; i++)
rsort(i, 15);
cout << "<radix_sort>" << endl;
for (int i = 0; i < 15; i++)
cout << A[i] << ' ';
cout << endl;
}
/////////////////////////////////////////////////////////////
void counting_sort()
{
int n = 10;
int arr[10] = { 1,3,5,6,8,2,4,10,7,9 };
int count[11] = {};
int sortarr[10] = {};
for (int i = 0; i < n; i++)
count[arr[i]]++;
for (int i = 1; i < 11; i++)
count[i] += count[i - 1];
for (int i = 0; i < n; i++)
{
count[arr[i]]--;
sortarr[count[arr[i]]] = arr[i];
}
cout << "<counting_sort>" << endl;
for (int i = 0; i < n; i++)
cout << sortarr[i] << ' ';
cout << endl;
}
int main()
{
selection_sort();
bubble_sort();
insertion_sort();
merge_sort();
quick_sort();
heap_sort(10);
radix_sort();
counting_sort();
return 0;
}